Brain2Music: Reconstructing Music from Human Brain Activity
Timo I. Denk∗1 Yu Takagi∗2,3
Takuya Matsuyama2 Andrea
Agostinelli1 Tomoya Nakai4
Christian Frank1 Shinji
Nishimoto2,3
1Google 2Osaka University, Japan 3NICT, Japan 4Araya Inc., Japan
Abstract The process of reconstructing experiences from human brain activity offers a unique lens into how the brain interprets and represents the world. In this paper, we introduce a method for reconstructing music from brain activity, captured using functional magnetic resonance imaging (fMRI). Our approach uses either music retrieval or the MusicLM music generation model conditioned on embeddings derived from fMRI data. The generated music resembles the musical stimuli that human subjects experienced, with respect to semantic properties like genre, instrumentation, and mood. We investigate the relationship between different components of MusicLM and brain activity through a voxel-wise encoding modeling analysis. Furthermore, we discuss which brain regions represent information derived from purely textual descriptions of music stimuli.
Please find the full paper on arXiv*Equal contribution; correspondence to timodenk@google.com and takagi.yuu.fbs@osaka-u.ac.jp
Music Reconstruction with MusicLM (Highlights)
| Stimulus (GTZAN music) | Reconstructions (generated by MusicLM) | ||
|---|---|---|---|

Comparison of Retrieval and Generation
| Stimulus | Retrieval | Generation with MusicLM | ||
|---|---|---|---|---|
| GTZAN music | From FMA | Gen #1 | Gen #2 | Gen #3 |
Comparison Across Subjects
| Stimulus | Retrieval (FMA) | Generation (MusicLM) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Stimulus | Subject 1 | Subject 2 | Subject 3 | Subject 4 | Subject 5 | Subject 1 | Subject 2 | Subject 3 | Subject 4 | Subject 5 |
Encoding: Whole-brain Voxel-wise Modeling
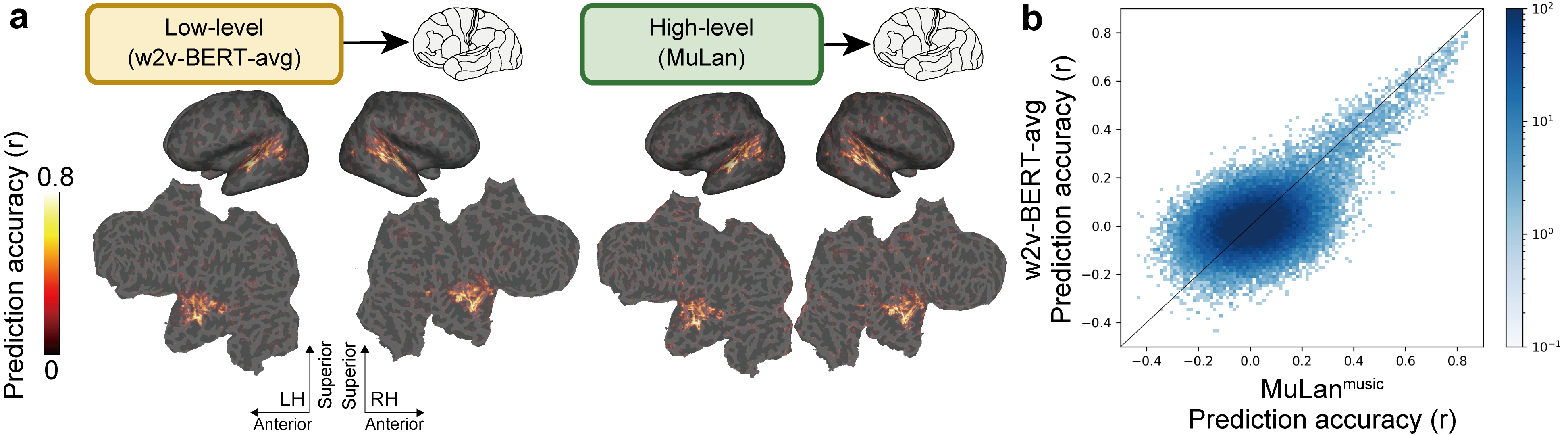
By constructing a brain encoding model, we find that two components of MusicLM (MuLan and w2v-BERT) have some degree of correspondence with human brain activity in the auditory cortex.
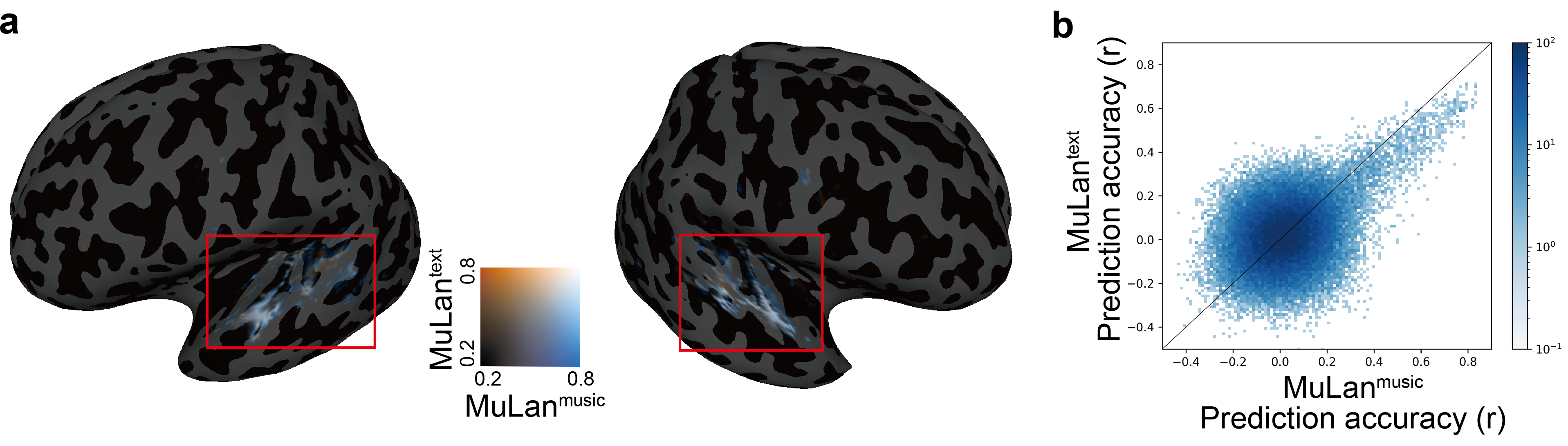
We also find that the brain regions representing information derived from text and music overlap.
GTZAN Music Captions
We release a music caption dataset for the subset of GTZAN clips for which there are fMRI scans. Below are ten examples from the dataset.
| Clip name | GTZAN music (15s slice) | Human-written text caption |
|---|---|---|
| blues.00017 | It is lazy blues with a laid-back tempo and relaxed atmosphere. The band structure is simple, with the background rhythm punctuated by bass and guitar cutting. The impressive phrasing of the lead guitar gives the piece a nostalgic impression. | |
| classical.00008 | Several violins play the melody. The melody is simple and almost unison, but it moves between minor and major keys and changes expression from one to the other. | |
| country.00012 | This is a classic country song. You can hear clear singing and crisp acoustic guitar cutting. The wood bass provides a solid groove with a two-beat rhythm. This is country music at its best. Ideal for nature scenes and homely atmospheres. | |
| disco.00004 | This music piece has a disco sound. Vocals and chorus create extended harmonies. The synthesiser creates catchy melodies, while the drumming beats rhythmically. Effective tambourine sounds accentuate the rhythms and add further dynamism. This music is perfect for dance parties, club floors and other scenes of dancing and fun. | |
| hiphop.00014 | This is a rap-rock piece with a lot of energy. The distorted guitars are impressive and provide an energetic sound. The bass is an eight beat, creating a dynamic groove. The drums provide the backbone of the rhythm section with their powerful hi-hats. The vocal and chorus interaction conveys tension and passion and draws the audience in. | |
| jazz.00040 | This is medium-tempo old jazz with female vocals. The band is a small band similar to a Dixie Jazz formation, including clarinet, trumpet and trombone. The vocal harmonies are supported by a piano and brass ensemble on a four beat with drums and bass. | |
| metal.00026 | This is a metal instrumental piece with technical guitar solos and distortion effects. The heavy, powerful bass creates a sense of speed, and the snare, bass and guitar create a sense of unity in unison at the end. It is full of over-the-top playing techniques and intense energy. | |
| pop.00032 | Passionate pops piece with clear sound and female vocals. The synth accompaniment spreads out pleasantly and the tight bass grooves along. The beat-oriented drums drive the rhythm, creating a strong and lively feeling. Can be used as background music in cafés and lounges to create a relaxed atmosphere. | |
| reggae.00013 | This reggae piece combines smooth, melodic vocals with a clear, high-pitched chorus. The bass is swingy and supports the rhythm, while whistles and samplers of life sounds can be heard. It is perfect for relaxing situations, such as reading in a laid-back café or strolling around town. | |
| rock.00032 | This rock piece is characterised by its extended vocals. The guitar plays scenically, while the bass enhances the melody with rhythmic fills. The drums add dynamic rhythms to the whole piece. This music is ideal for scenes with a sense of expansiveness and freedom, such as mountainous terrain with spectacular natural scenery or driving scenes on the open road. |
FAQ
General
Could you describe your paper briefly?
In this paper, we explore the relationship between the observed human brain activity when human subjects are listening to music and the Google MusicLM music generation model that can create music from a text description. As part of this study we observe that
- When a human and MusicLM are exposed to the same music, the internal representations of MusicLM are correlated with brain activity in certain regions.
- When we use data from such regions as an input for MusicLM, we can predict and reconstruct the kinds of music which the human subject was exposed to.
Are there studies of brain decoding and encoding for music, or more generally for sound processing? What is new about this study?
Previous studies have also examined the human brain activity while participants listened to music and discovered musical feature representations in the brain. Given the recently published music generation models such as MusicLM, it is now possible to study whether human brain activity can be converted into music with such models.
Methods
What is MusicLM?
MusicLM is a type of language model that was trained on music and can be used to create music given a text describing the desired music or other inputs such as a hummed melody together with some text describing the style of the desired music. It is based on a generic framework called AudioLM, which uses language models to generate audio at high fidelity. You can try out MusicLM in Google Labs.
What brain data did you use?
We used functional magnetic resonance imaging (fMRI). This technique is detecting changes associated with blood flow and relies on the fact that cerebral blood flow and neuronal activation are connected. That is, it looks for indicators of changed blood flow and uses those to measure brain activity in the regions of interest.
Limitations
There are three main factors that are currently limiting the quality of the reconstructed music when observing human brain signals:
- the information contained in the fMRI data is very temporally and spatially sparse (the observed regions are 2×2×2mm3 in size, many orders of magnitude larger than human neurons).
- the information contained in the music embeddings from which we reconstruct the music (we used MuLan, in which ten seconds of music are represented by just 128 numbers).
- the limitations of our music generation system. When we studied MusicLM, we saw that it has room to improve both in the way it adheres to the text prompt and in terms of the fidelity of the produced audio.
Could the model be transferred to a novel subject?
Because the brain’s anatomy differs from one person to the next, it is not possible to directly apply a model created for one individual to another. Several methods have been proposed to compensate for these differences, and it would be possible to use such methods to transfer models across subjects with a certain degree of accuracy.
What are the ethical/privacy issues that stem from this study?
Note that the decoding technology described in this paper is unlikely to become practical in the near future. In particular, reading fMRI signals from the brain requires a volunteer to spend many hours in a large fMRI scanner. While there are no immediate privacy implications from the technology as described here, as with this study, any such analysis must only be performed with the informed consent of the studied individuals.
Outlook
What are the future directions?
Note that in this work, we perform music reconstruction from fMRI signals that were recorded while human subjects were listening to music stimuli through headphones. More sophisticated technology to examine the human brain will further advance the research in this area and the model’s capability to generate music matching the heard stimulus. An exciting next step is to attempt the reconstruction of music or musical attributes from a person’s imagination.
What are the potential applications?
With the amount of work required to obtain fMRI signals from the brain, we do not have direct applications in mind. This work has been motivated by a fundamental research question: Does the MusicLM music generation model contain components that are mirrored in the human brain, and if so, which are those? And if such connections exist, how would music sound like that is inspired by signals from the human brain?