AudioScopeV2: Audio-Visual Attention Architectures
for Calibrated Open-Domain On-Screen Sound Separation
| Efthymios Tzinis1,2,* | Scott Wisdom1 | Tal Remez1 | John R. Hershey1 |
| 1Google Research |
| 2University of Illinois at Urbana-Champaign |
| *Work done during an internship at Google. |
Abstract
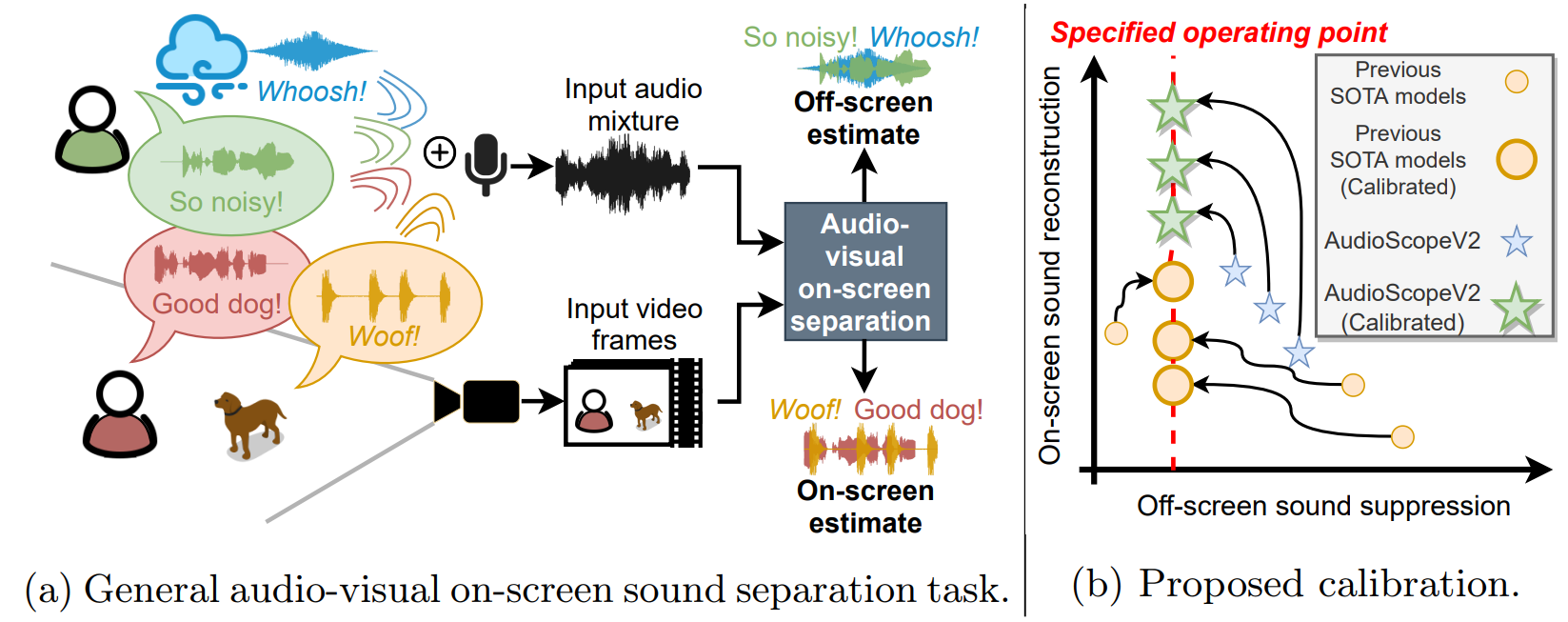
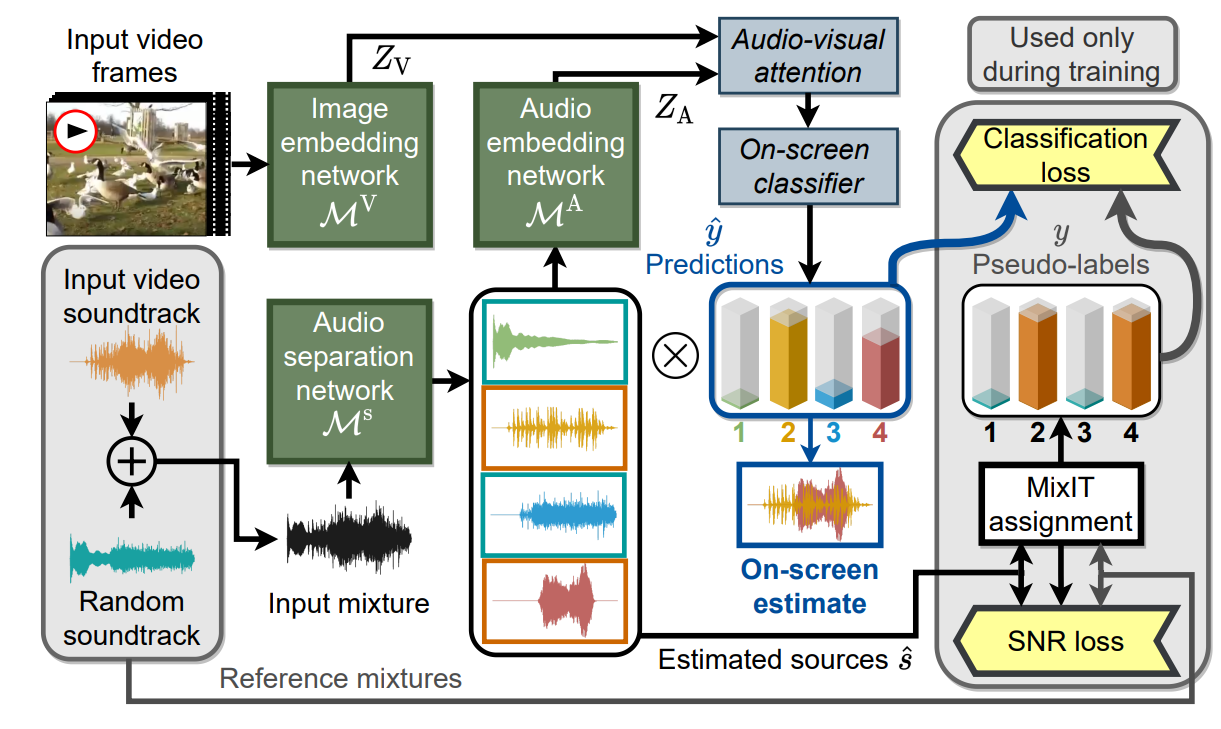
We introduce AudioScopeV2, a state-of-the-art universal audio-visual on-screen sound separation system which is capable of learning to separate sounds and associate them with on-screen objects by looking at in-the-wild videos. We identify several limitations of previous work on audio-visual on-screen sound separation, including the coarse resolution of spatio-temporal attention, poor convergence of the audio separation model, limited variety in training and evaluation data, and failure to account for the trade off between preservation of on-screen sounds and suppression of off-screen sounds. We provide solutions to all of these issues. Our proposed cross-modal and self-attention network architectures capture audio-visual dependencies at a finer resolution over time, and we also propose efficient separable variants that are capable of scaling to longer videos without sacrificing much performance. We also find that pre-training the separation model only on audio greatly improves results. For training and evaluation, we collected new human annotations of on-screen sounds from a large database of in-the-wild videos (YFCC100M). This new dataset is more diverse and challenging. Finally, we propose a calibration procedure that allows exact tuning of on-screen reconstruction versus off-screen suppression, which greatly simplifies comparing performance between models with different operating points. Overall, our experimental results show marked improvements in on-screen separation performance under much more general conditions than previous methods with minimal additional computational complexity.
Paper
"AudioScopeV2: Audio-Visual Attention Architectures for Calibrated Open-Domain On-Screen Sound Separation", |
Demos
| Demo index |
Dataset Recipe
| Unfiltered dataset recipes on GitHub |
Last updated: July 2022