Overview
End-to-End Diffusion

We train a series of diffusion models that are applied in succession to generate the final music clip.
Pseudo-labeling for Training Data Generation
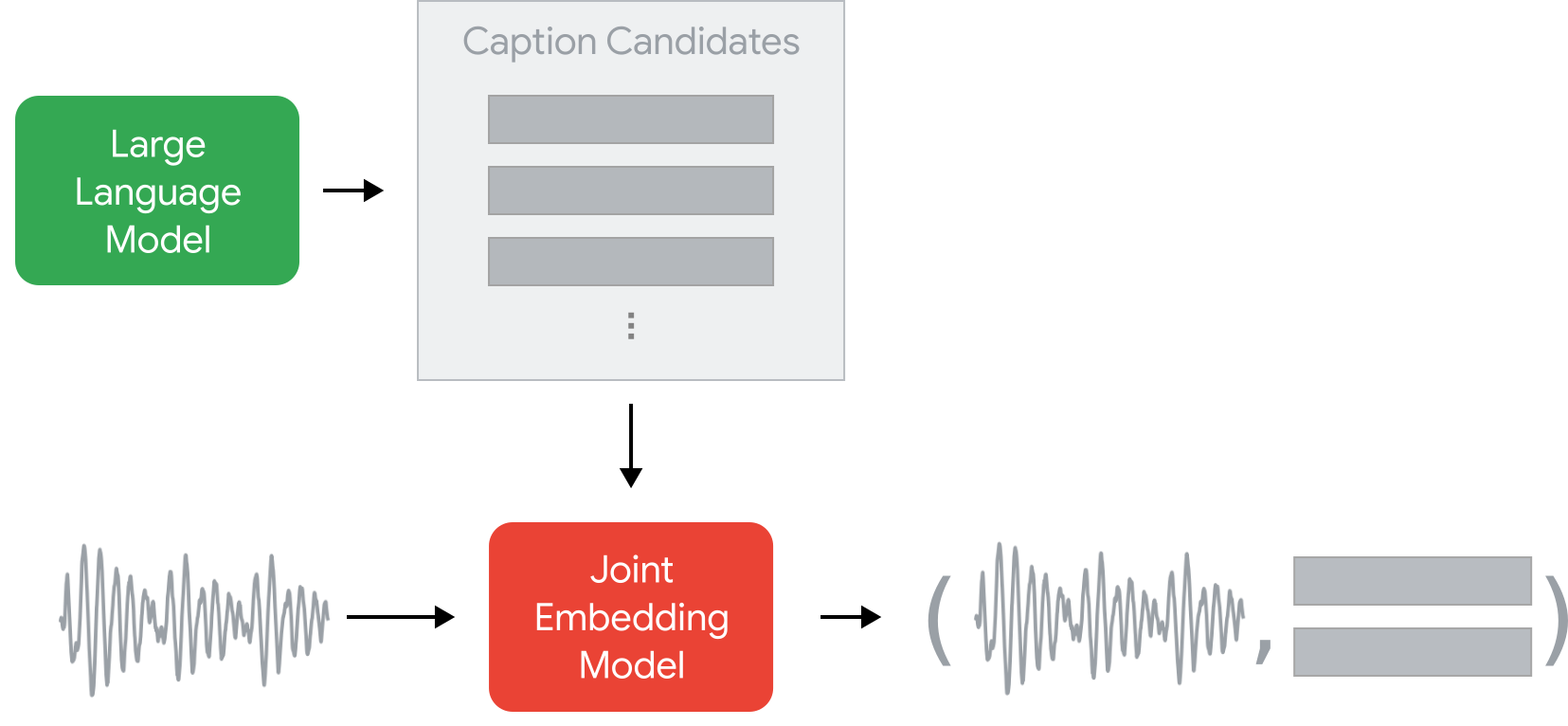
The training set is generated by pseudo-labeling a large unlabeled set of music audio using two deep models. A large language model is used to generate a large set of generic music descriptive sentences as caption candidates. A pre-trained music-text joint embedding model is used to assign the captions to each music clip via zero-shot classification.
Generative Ability
Noise2Music models are able to go beyond simple music label conditioning and handle complex, fine-grained semantics.Generative ability grounded on semantically rich text prompts
| Prompt | Waveform Model |
| Powerful tune with pop, rock influence with strong synthesizers for an introduction music to a sporting event. | |
| A funk song with rhythmical guitars using wah pedals, a horn section, a strong bass line and husky vocals. | |
| Smooth soft R&B song with tender vocals, romantic piano and groovy, funky bass. | |
| Bright, cheerful and groovy song featuring the piano that sounds like an opening theme for a comedy series. | |
| A female contralto singing a slow jazz ballad at a live performance. | |
| A pop song featuring African drumming polyrhythm. | |
| A soaring 90's pop love song with explosive female vocals hitting high notes. | |
| Moody jazz music with a basic formation (drums, contra bass, piano and trumpet) with a melancholy trumpet solo. | |
| Modern fusion instrumental music influenced by traditional Chinese music with a wistful tone. | |
| Grungy, but melodic and melancholy rock music with electric guitar and vocals. | |
| Folk song with two singers harmonizing with acoustic guitars that can be used as a commercial jingle. | |
| Classical music with horns and trumpets that can be used as an entrance song for a ceremony. | |
| Medium tempo hard rock music with a 70's vibe. The drum beat is heavy and technical, the bass line is steady while the guitar sound is hard and distorted. The vocalist has a strong, raspy voice. | |
| Electronic dance music with chill vibes featuring water sounds and violin. | |
| A male singer with a rough voice singing the climax of a power ballad to the tune of the acoustic guitar. | |
| A fast, complicated, technical song with clear sound production value that sounds like music from a video game boss battle. | |
| Middle eastern instrumental music for meditation, with the flute taking a lead role in the arrangement. | |
| This is music that would be played at the climax of a movie. Dramatic, stirring orchestral music is amplifying the emotion of the scene. |
Representation of key musical attributes
Ablation Attribute
| Prompt | Waveform Model | Spectrogram Model |
| Moody, melancholy medium-tempo standard jazz song that is good for late-night listening. | ||
| Moody, melancholy medium-tempo fusion jazz song that is good for late-night listening. | ||
| Moody, melancholy medium-tempo blues that is good for late-night listening. | ||
| Orchestral classical music to listen to while focusing on homework. | ||
| EDM music to listen to while focusing on homework. | ||
| A romantic love song played by a band with a lead piano. | ||
| A romantic love song played by a band with a lead saxophone. | ||
| A sad song played by a symphony orchestra. | ||
| A sad song played by a solo pianist. | ||
| A sad song played by a solo acoustic guitarist. | ||
| Slow-paced progressive rock instrumental video game music with electric guitars, keyboards, bass and drums. | ||
| Rapidly-paced progressive rock instrumental video game music with electric guitars, keyboards, bass and drums | ||
| Fast electronic dance music with a cool and chic vibe. | ||
| Up-beat electronic dance music with a cool and chic vibe. | ||
| Slow dance music with a cool and chic vibe. | ||
| Funky, bright and happy song with smooth, soulful male vocals. | ||
| Romantic song with smooth, soulful male vocals. | ||
| Uplifting orchestral music. | ||
| Suspenseful orchestral music. | ||
| A mid-tempo R&B song featuring a catchy hook with smooth male vocals. | ||
| A mid-tempo R&B song featuring a catchy hook with smooth female vocals. | ||
| A melancholy country song with strong, powerful vocals. | ||
| A melancholy country song with soft female vocals. | ||
| Song that sounds like rock music from the 70's, with bass, drum, guitar and vocals. | ||
| Song that sounds like rock music from the 80's, with bass, drum, guitar and vocals. | ||
| Song that sounds like rock music from the 90's, with bass, drum, guitar and vocals. | ||
| Song that sounds like rock music from the 2000's, with bass, drum, guitar and vocals. | ||
| Song that sounds like pop dance music from the 70's, with female vocals. | ||
| Song that sounds like pop dance music from the 80's, with female vocals. | ||
| Song that sounds like pop dance music from the 90's, with female vocals. | ||
| Song that sounds like pop dance music from the 2000's, with female vocals. |